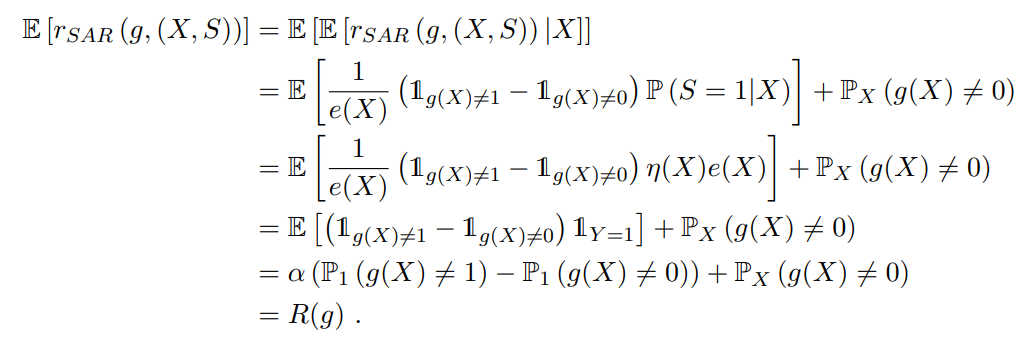Introduction
PUの利用例として、病院での診断、機械のデザインの補助、スパム検出、テキスト分類、遺伝病検出、異常検出などがある。機械における疲労設計では、テストを行うが、壊れたをPositive壊れなかったをUnlabeledとして扱うほうがいいね(壊れなくても疲労テストの時間を延ばせば壊れるかもしれないので)。
PUの今までの手法については、📄 2020-Survey-Learning from positive and unlabeled data: a survey を参考するとわかりやすい。ここにある2 steps techniqueは経験的には良い結果が得られるが性能の保証はなされていない。
2020-Survey-Learning from positive and unlabeled data: a survey を参考するとわかりやすい。ここにある2 steps techniqueは経験的には良い結果が得られるが性能の保証はなされていない。
それ以外は基本的には、Cost-sensitiveと言って導き出した式を最小化するというものである。そこでは基本的には、Selected Completely At Random(SCAR)、どの y=+1の点でも、ラベルがつく s=+1の確率は常に等しいという仮定である。
だが、SCARが適応できない場合が多い。選択バイアスがある以上、Selected At Random(SAR)という仮定も考えられている。そこでは、各点が選ばれる確率は一様ではない。
誤差の上界はMcDiarmidの不等式などを使うことで、訓練サイズ nとしたら、 O(1/n)のオーダで減ることが知られている。さらに、「決定境界から遠いほど、より確実にそのクラスに属する」Margin Assumptionを元にすればもっと精密に 1/nのオーダにすることができるらしい。
Case-Controlシナリオについて、du Plessisらの研究によって、上界のオーダは O(1/nP+1/nU)であるとわかっている。npはpositiveの数、nuはunlabeledの数。
この研究では、Single-Training-Setにおける、選択バイアスがある=SAR条件下でのリスク上界を評価している。Noisy Labelにも対応しているのがすごいところ。
Standard Classification Setting
問題設定
PN Learningにおけるcost-sensitiveの問題設定。 xに対して、 y=+1がPositive、 y=0がNegativeだとする。π=p(y=+1)とすると、以下のように指定のデータ xについて、正しく分類できた確率をこのように分解して書くことができる。
px=(1−π)p(x∣y=0)+πp(x∣y=+1) 最終的な目標は
g=argmingR(g)=argmingp(g(x)=y) ベイズ分類器についての簡単な説明
p(ラベル∣データ)を計算し、ある閾値を超えるかどうかで判断基準とする。
例として、スパムかどうかの二値について、 (x1,x2,y)の訓練データを与えられているとする。次の順番で求める。
- 事前確率 p(y)を求める。これは訓練データの比から簡単にわかる。
- 各クラスの中でのパラメタ x1,x2が指定の値をとるときの条件付確率、 p(x1=a∣y)を求める。
- ベイズの定理を用いることで、 p(x1=a∣y),p(x2=b∣y)から、 p(y∣x1=a,x2=b)を得る。
- ここでは x1,x2は独立だと仮定しているが、そうじゃないときでもまあやりようはある。
- これで得た p(y∣x1=a,x2=b)はベイズ分類器である。これが0.5を超えたら、みたいな基準で作る。
これは離散値の予測であるが、そもそも連続値の予測であるならば、重回帰すればよい。
また、ベイズ回帰とは、ベイズ統計でパラメタの事前分布を仮定して、観測結果を受けての事後分布がどうなったか?を得るものである。
η(x)=p(y=+1∣x=x)、つまり指定されたデータ xが与えられたときに、Ground Truth LabelがPositiveである確率を設定する。(これ自体ベイズ分類器といってもいいが 多分これは重回帰しているかな?)単純ベイズ分類器 g∗は以下のように定式化できる。 1/2以上となったらラベルが付く感じ。
g∗=1η(x)≥1/2 ベイズ分類器における最適の g∗(最も正確に表すことができている分類器 所属してるモデルを問わず一番よいもの)との誤差を示すために、以下のようにexcess riskを定義する。
l(g,g∗)=R(g)−R(g∗) だが、真の πも p(x∣y=0)なども知りようがないため、実際はよさげなモデルを使っていくことになるし、損失関数 Rも経験的に与えられた訓練データから計算するので、 R^となる。つまり、あらかじめモデル Gを指定したうえで、経験的な損失 R^においての最適というのが考えられ、次のようになる。
g^=argming∈GR^(g) これを加味したとき、excess riskは次のようになる。 gGは真の損失関数 Rにおける、モデル Gでの最適な分類器。
l(g^,g∗)=R(g^)−R(g)=(R(g^)−R(gG))+(R(gG)−R(g)) 前半はStatistical Error, 後半はApproximation Errorという。後半はどうしようもないとして、前半のStatistical Errorの最小化を頑張りたいと考える。(なので、真の g∗もこの際 g∗∈Gに入ってるものとする)
また、このl(g^,g∗)は真の損失 Rを介して、 p(x∣y=0)にも依存し、そして g^の由来のように訓練データにも依存している。(それはそうだ)
Risk Bounds in the Standard Classification Setting
Statistical Errorの R(g^)−R(g)の収束について、以下のようにVC次元で評価した式が成り立つ。参考資料はこちら。 p∼P(G)は、真の確率 p(x∣y=0)がわからない以上、どんなものであってもその中での最大値、という意味である。
supp∼P(G)E[l(g^)−l(g∗)]≤C1nV C1は定数であり、 VはVC次元。
これをさらに拡張して、 ηが中心の1/2からすべての入力 xについて、 y=+1,0のサンプルを問わず、常に少なくとも h>V/nだけ離れているとする。
supp∼P(G,h)E[l(g^PU,g∗)]≤C2nhV(1+log(Vnh2)) マージンの hが大きくなるほど、分類がしやすくなり、収束率が 1/nまで上昇する。しかし、 h<1/nならば、この章の最初の式で評価するほうがよくなる。つまり収束率は 1/nになる。
これをこの論文の証明ではしっかり使っているので重要だ。
PU Learningにおける文脈
PUでは、ラベルがついているは s=+1、ついてないは s=0である。ラベルがついているのならば、必ずPositiveである、でもある。 1=p(y=+1∣x,s=+1)
ここで、propensity scoreというものを導入する(先行研究2019 Bekkerらが因果推論から持ってきたやつかな)。Ground Truth LabelがPositiveだとわかっている各点に対して、ラベルがつく確率というものである。
e(x)=p(s=+1∣y=+1,x=x)p(s=+1∣y=0,x=x)=0 下の式は、Negativeがラベルがつく確率はないということである。
ここで、 η(x)=p(y=+1∣x=x)とすれば、実際にデータ xに対してラベルがつく確率の η^(x)は以下のように書くことができる。最後の式変形は、ラベルがつくならば必ず y=+1であることを利用した。
η^(x)=e(x)η(x)=p(s=+1∣x=x,y=+1)p(y=+1∣x=x)=p(y=+1,s=+1∣x=x)=p(s=+1∣x=x) ラベルがつく確率は上記のように、propensity scoreと真のPositiveである確率の積から成る、というものだ。
SCAR仮定
SCARでは、すべての y=+1のサンプルは一様に選択されるので、 e(x)=c(定数)といえる。このことから、 p(x∣y=+1,s=+1)は常に同じ定数である。
SAR仮定
選択バイアスがあるとき、 e(x)はみな同じになるわけではない。これが難しいところ。
PU Learningにおけるバイアスの問題
昔から試された手法としては、 s=+1をPositive、 s=0をNegativeとしてPN Learningする(重みづけを変えるとかして)というのがある。この時学習を重ねるとうまく p(s=+1∣x=x)=η^(x)を学習できるだけだが、我々が欲しいのは p(y=+1∣x=x)=η(x)なので、そもそも収束対象が違うわけだ。
だが、収束対象が違うといっても、PU Learningの学習はノイズには十分にrobustである。Canningsら(2020)が示したように、以下の条件で、 η^(x)を予測する不偏学習器は、根本的に違うものを予測したにもかかわらず、 η(x)に収束するとね。
e(x)≥2η(x)1,∀x∈Rd∩η(x)≥21 気持ちとしては、 η^(x)=e(x)η(x)の式で、 ηの結果からそもそもがPositiveであるデータに対して、式の乗算結果が1/2を超える=ラベルがつくと判定されることができれば、そりゃ収束するよねというもの。
つまり、この条件さえ満たすことができれば、クッソ雑な昔ながらの s=+1をPositive, s=0をNegativeの分類器で学習させても正しく学習できるってことだ!(効率は知らないが)
この条件下では、分類が難しい= η(x)が1/2に近いようなものに対しては、propensity scoreの e(x)は1に十分に近くなければならないということも示している。また、条件たちを総合すれば、propensity scoreは η(x)の可動域を考えると、
e(x)∈[1/2,1] こうなり、Positiveの各サンプルに対して、絶対にpropensity scoreは1/2以上という意味でもあるわけだ。
ここで、SAR仮定に立ち返って考えてみる。観測が難しいデータほどpropensity score e(x)が低くなるので、観測が難しいPositiveのデータに対して e(x)≥1/2となることはできない。
なので、上の条件は役に立つようには見えるけどいうほどたたないってそれ一番言われているから。これよりも汎用性の高い式を見つけてから、収束率などの評価をしたほうがいいのではないか。
SCARにおける不偏経験的損失最小化
SCARでは、 ∀xにて、 e(x)=ecの定数で表せた。
🚫
Post not found でDu Plessisら示してるように、Case Controlシナリオでは、以下のように分類失敗する確率=リスクを書くことができ、これを s=+1,0のデータだけで書き直せるとした。
R(g)=πEP[l(g(x,+1))]+(1−π)EN[l(g(x),0)]=π(EP[l(g(x),+1)]−EP[l(g(x),0)])+EX[l(g(x),0)] ここで、 lは2つの引数が同じならば0、そうじゃないならば1を返す01損失だとすれば、全体における分類ミス率は R(g)となる。実際は代替損失でやるしかないが。
この式の形から見れば、 s=0をNergativeとして扱い、 s=+1はPoisitiveとNegativeの両方として扱っていて、そのうえで重みをつけて処理しているという扱い。
ここで、 以下のように書き直せる。
π=p(y=+1)=p(s=+1∣y=+1)p(s=+1) よって、経験的に R(g)を求めるのは、SCARでは以下のように行うことができる。
R^SCAR(g)=n1∑i=1n[ec1si=+1(l(g(xi,+1))−l(g(xi),0))+l(g(xi),0)]=nP+nUnP⋅nP1∑i=1nP[ec1(l(g(xi,+1))−l(g(xi),0))]+nP+nUnU⋅nU1∑i=1nU[l(g(xi),0)] ここまでの話を踏まえると、SCARでのリスク最小化では、クラス事前確率 or propensity scoreが必要。
SAR仮定におけるRisk最小化
2019 Bekkerらの論文にあった、Propensity Scoreを用いた最小化。
SARではさらに仮定が必要になる。先行研究では
- 2018 He e(x)は η(x)=p(y=+1∣x)から見て、増加関数である。
- 2020 Bekker, 2021 Gong はPropensity Scoreをパラメトリックなモデルから推測する。
この論文では、2020 Bekkerの方法を拡張して、 s=+1のサンプルについてのみ、Propensity Scoreがわかっている状態でのSAR仮定の下でのPU learningについて考えている。割と限定的じゃないか、と思うかもしれないが意外にそうでもない。
まず、Bekkerらも示した、上の η^(x)=p(s=+1∣x)=p(s=+1∣x,y=+1)p(y=+1∣x)=e(x)η(x)をもとに代入すると、損失関数は以下のようになる。
R(g)=e(x)p(s=+1∣x)(l(g(x),+1)−l(g(x),0))+l(g(x),0) さきほどの定数だった ecを代わりに定数ではない、Propensity Score functionの e(x)にしただけである。これを経験的に得たものを R^nSARとする。 n個のデータを用いてる感じ。
Bekker2020らは、R^nSARと R^nとの誤差上界を評価していたらしい(読み直す)が、この論文ではさらに一歩進んで、R^nSARと真のリスク関数 Rとの誤差上界を評価したい。
下のように、R^nSARは Rの不偏推定量である。
だから、 s=+1のサンプルのPropensity Scoreさえ正しく知ることができれば、SARでも真の R(g)に近づくことが、できるんですよね(真理)
Main Results
今までの話の流れを踏まえて、この論文で語っていきますよ。SAR仮定の下でのね。
モデル Gに含まれる識別器の中で、経験損失 R^nSARについて、以下のように最適なものを学習によって得ることができる。
g^PU∈argming∈GR^nSAR(g) そして、理想の R(g)との差をと定義する。
RnSARˉ=R^nSAR−R(g) PU LearningのSAR仮定のもとでのExcess Riskの上界
Bekkerらは Gが有限集合であるときの、誤差の上界の評価を行った。この論文では、無限集合に拡張したうえで、propensity score function e(x)の影響も加味したものの証明となっている。
無限集合になったとしても、 Gが無限集合であろうとも、VC次元が無限ではないのであれば扱うことができるのだ。
また、separabilityという仮定があり、モデル Gに含まれる関数列 {gi}i=1kがあって、すべての訓練データについて、以下の式のようにその関数列で理想的な gへと収束することができるとする。
rSAR(gk,(x,s))→k→∞rSAR(g,(x,s)) 分類タスクの難しさを明示的に示すため、Excess Riskの上限を考えたい。この時、以下のように ∣2η(x)−1∣を基準にして考える。
∃h>0,∣2η(x)−1∣≥h ここでの xはすべて y=+1のサンプルだと考えているので、最低でも η(x)=p(y=+1∣x)は1/2以上でなければならない。
この仮定を論文の中ではMassartマージン仮定という。2006 Massartの提案したものに基づくらしい。
定理1 SAR仮定におけるPU Learningのリスクの上界
g^PU∈argming∈GR^nSAR(g) 指定のモデル Gと n個の訓練データサンプルを与えられたとき、もっともリスクを減らせる識別器 g^PUを考える。
理想の リスク関数をとるようなgへ収束するある関数列 {gi}i=1kがあり、Massartマージン仮定によって、 η(x)=p(y=1∣x)が ∣2η(x)−1∣≥hを満たすとする。この時、誤差上界は以下のようになる。
E[l(g^PU,g∗)]≤κ1min(nemhV(1+logmax(Vnh2,1)),nemV) κ1は何かしらの定数。 emはすべてのありうるデータに対して、 p(k=+1∣x,y=+1)の下界。
この定理からは、 h≥V/nemを満たすのならば、誤差の上界は O(nhemV)となる。そうではない場合は、 O(nemV)となる。
これは普通の二値分類におけるMassart 2006と似ている。 em=1となっているときはすべての y=+1のサンプルが s=+1であるということなので、二値分類のと同じ結果になる。逆に、 emが低いのならば、上界は大きくなってしまう。
この結果からもわかる通り、PU Learningは emの存在があることから、PN Learningと比べて上界を悪化させることになる。ラベルがつくPositiveが多いほど上界が抑えられるし、だからラベルが大してつかないとPU Learningは難しくなる。
Minimax Riskの下界
先ほどの学習では上界を見つけたが、これは g^PUについてのもの。本当にこれが最適な識別器なのか?を示したい。
Minimax Riskとは、最悪のサンプルを与えられたときの、最良の分類器を訓練した時のrisk。次のように書ける。つまり、先ほどの下限と考えていい。
R(G,h)=infg^∈G[supP∼P(G,h)E[l(g^,g∗)]] このMinimax Riskの上界に関しては、明らかに先ほど導出した以下の式である。
E[l(g^PU,g∗)]≤κ1min(nemhV(1+logmax(Vnh2,1)),nemV) では下界はどうなっているのか?
定理2 SCAR仮定におけるMinimax Riskの下界
VC次元 V≥2だとして、 nem≥Vだとする。SCARなので、 e(x)=emとする。ある定数 κ2によって記述できるとする。
ifh≥nemV:R(G,h)≥κ2hnemV−1;ifh<nemV:R(G,h)≥κ2nemV−1. nemは全体の中で占めるラベル付きの例の数。このことから、 g^PUは正しい選択だったとわかる。
SARに定理2を拡張するには
次の仮定を考える。
∀ϵ>0,∃(x1,⋯,xV)∈(Rd)V:supi∈{1,⋯,V}e(xi)≤em+ϵ どんな小さな値でも、 emにそれを足せば propensity score function e(xi)はそれ以下となるような、VC次元 Vだとすると V個のサンプルを必ず見つけられる。
この過程を満たす限り、SAR仮定でも、同様にSCAR仮定と同じようなMinimax Riskの下界を得ることができる。